Hala Pulse (STHT1)
Maximum AI Power,
Minimum Footprint
The Hala Pulse packs a 16-core AMD Strix Halo processor into a 1-litre metal chassis. With USB4 at 40 Gbps, Oculink eGPU support, and three configurable power modes, it delivers enterprise-grade local AI inference anywhere you need it.

Built For Serious AI Work
Enterprise-grade AI compute in a chassis smaller than a coffee mug.
16-Core Strix Halo CPU
AMD FP11 with 16 high-performance cores and 120W TDP. Runs demanding AI workloads and multi-threaded inference with ease.
Navi 3.5 Graphics — 20 WGP
Integrated Navi 3.5 with up to 20 Work Group Processors. Handles AI rendering, content creation, and GPU-accelerated inference.
Oculink eGPU Expansion
PCIe 4.0×4 Oculink port for external GPU docking. Scale to discrete-class compute when your workload demands it.
USB4 + WiFi 7 Connectivity
Dual USB4 at 40 Gbps, HDMI 2.1, WiFi 7, and 2.5G Ethernet. Future-proof I/O for any deployment scenario.

1 Litre. 16 Cores.
Zero Compromise.
The Hala Pulse squeezes a full 16-core Strix Halo processor, Navi 3.5 graphics, and quad-channel LPDDR5x into a metal chassis that measures just 160 × 160 × 47 mm. Add an external GPU via Oculink when you need discrete-class performance — or run it standalone for silent, always-on AI inference.

🚀16-Core AI Processing
- AMD Strix Halo FP11 — 16 high-performance cores
- 120W sustained TDP in Performance mode
- Balanced (65W) and Quiet (35W) modes for flexible deployment
🖥Navi 3.5 Integrated Graphics
- Up to 20 Work Group Processors (WGP)
- HDMI 2.1 FRL output for 4K/8K displays
- Oculink PCIe 4.0×4 for external GPU docking
🧠High-Bandwidth Memory & Storage
- LPDDR5x — 4 channels at up to 8000 MT/s
- 2× M.2 2280 PCIe 4.0×4 NVMe SSD slots
- SD 4.0 card reader for dataset ingest
Endless Possibilities With The 16-Core Hala Pulse

On-Premise LLM Deployment
Run large language models locally with zero cloud dependency — full data sovereignty for regulated industries.
Scalable eGPU Inference
Connect an external GPU via Oculink and unlock discrete-class training and batch inference throughput.
Edge AI Gateway
Deploy at the network edge for real-time inference, smart analytics, and autonomous decision-making.
Silent 24/7 AI Server
Switch to 35W Quiet mode for always-on, whisper-silent operation as a dedicated AI endpoint.
One Litre. Every
Use Case.
From the developer's desk to the server rack, the xN88 adapts to your workload. Pair it with an eGPU for heavy training, run it standalone for always-on inference, or cluster multiple units for distributed computing — all in a whisper-quiet 1L form factor.
AI Research & Inference
Run and fine-tune LLMs locally with 16 cores and expandable GPU compute via Oculink.
- Local Model Training
- Batch Inference
- RAG Pipelines
Content Creation Studio
Navi 3.5 graphics power real-time 3D rendering, video editing, and AI-assisted production.
- 4K/8K via HDMI 2.1
- GPU-Accelerated Editing
- AI Upscaling
Edge & IoT Gateway
At just 1L, deploy at the edge with WiFi 7, 2.5G Ethernet, and silent 35W mode.
- Smart Building AI
- Real-Time Analytics
- Autonomous Sensors
Enterprise & Security
TPM, Kensington lock, Windows 11, and triple power modes for regulated environments.
- Data Sovereignty
- Zero-Trust Endpoints
- HIPAA / GDPR Ready
Key Specifications
Everything packed into 1 litre of precision-engineered metal
Processor
16 Cores
AMD Strix Halo FP11 with 16 high-performance cores. Three power modes: 120W Performance, 65W Balanced, and 35W Quiet.
Compatibility: Supports: Llama, DeepSeek, Qwen, Mistral, and all major OSS LLMs
Graphics
Navi 3.5
Up to 20 WGP
Memory
LPDDR5x
4-ch @ 8000 MT/s
Storage
2× M.2 2280
PCIe 4.0×4 NVMe
Front I/O
2× USB4
40 Gbps · SD 4.0
Expansion
Oculink
PCIe 4.0×4 eGPU
Networking
WiFi 7
2.5G LAN · BT 5+
Display
HDMI 2.1
FRL · 4K/8K output
Chassis
1 Litre
160×160×47mm metal
Ready To Deploy The Hala Pulse?


Check More Products
Tools and strategies modern teams need to help their companies grow.

Hala Nexus(STHT1)
Next-generation AI edge computing with industry-leading performance.

Hala Core(STHT1)
Apple-compete mini PC with USB4 V2 80Gbps, 10G LAN, and built-in speakers in a 127mm metal chassis.

Hala Apex(STHT1)
Discrete RX 7600 XT 16GB mini PC with AMD Hawk Point CPU, triple-fan cooling, and 336W internal ATX PSU.
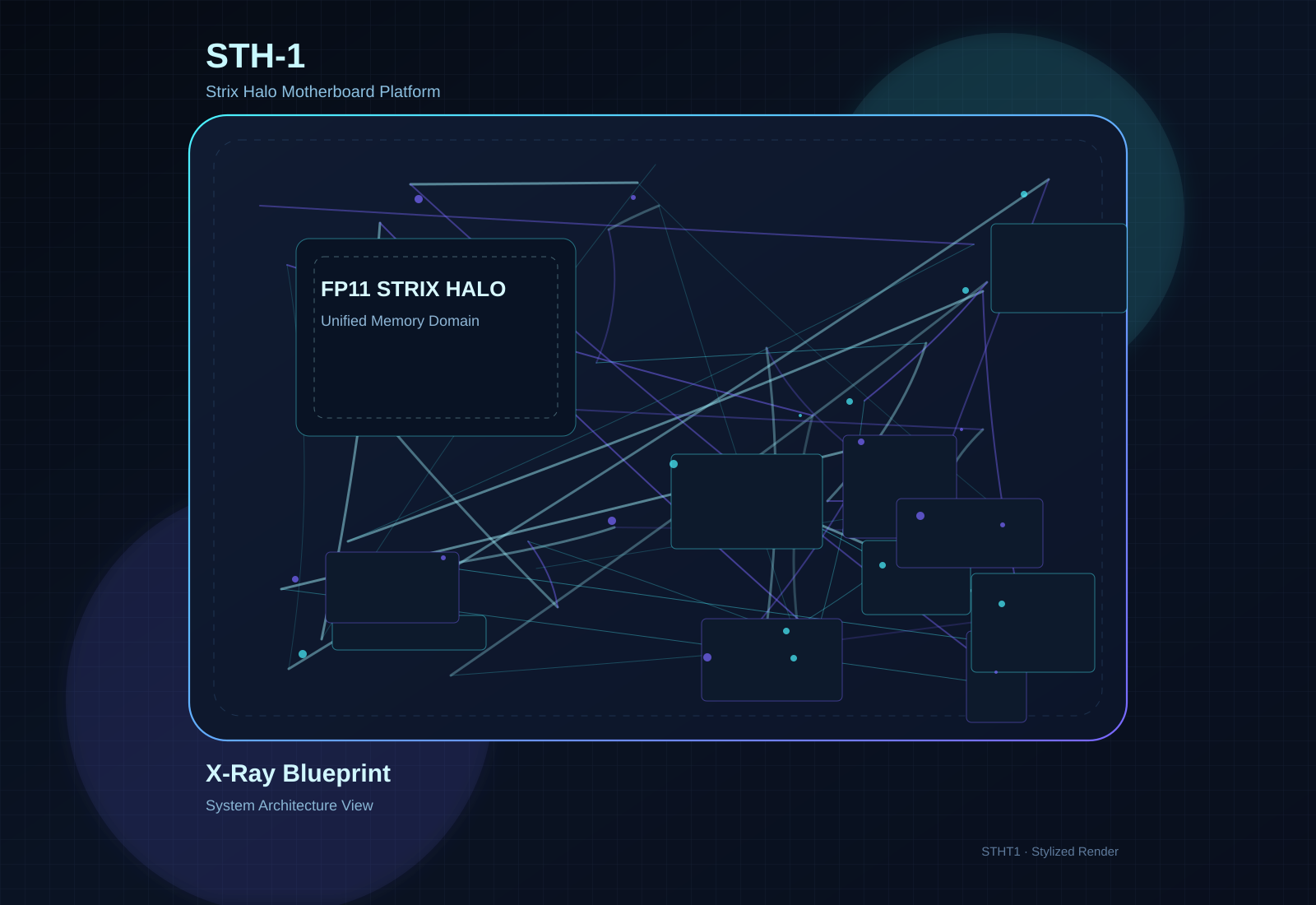
Motherboard STH-1
Thin Mini-ITX Strix Halo motherboard with up to 128GB LPDDR5X, dual M.2, and dual HDMI 2.1.
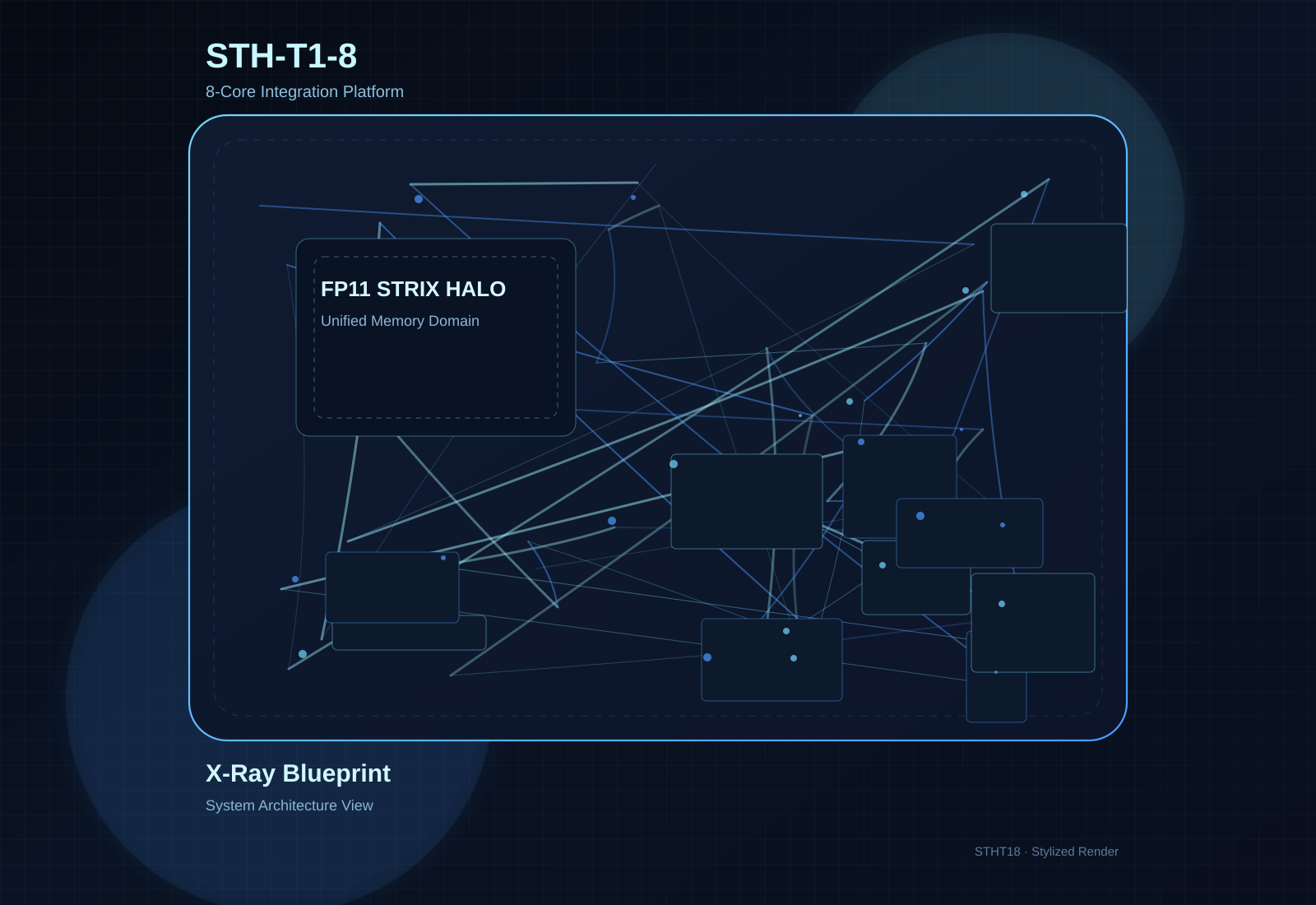
Motherboard STH-T1-8
8-core Strix Halo motherboard configuration with 128GB LPDDR5X, dual M.2 PCIe 4.0 x4, and 19V DC-in.